Task 2: Part C -the application#
Your software application (the “app”) is the entirety of part C of task 2. However, the Computer Science capstone is not a software project. Other than requiring you to apply machine learning (ML) to data, they will only assess what your application does -not its presentation.
Tip
The official rubric and directions were written to map the project’s elements to specific competencies. However, to allow for a broad range of projects its language is necessarily also broad. For more specifics, we recommend referring to the guidelines on this webpage and the Task 2 template.
What does the application need to do?#
Your app must help the user solve the organizational problem from task 1 by doing the following:
Data → ML model: Use data to develop a machine learning model.
Accuracy Metric: Provide an appropriate metric or plan for measuring the app’s accuracy.
Visualizations: Present 3 different pictures; images can code generated or static.
User Application: Provide a way for the “user” to use the ML model towards solving the problem.
The App: A standalone Jupyter Notebook file (.ipynb) which can predict Iris types (see the example).
Data → ML model: Labeled Iris petal dimensions train an SVM classification model.
Accuracy Metric: Percent of correct predictions on testing data.
Visualizations: Histograms showing distributions of different flower features and a confusion matrix illustrating the accuracy of the classification model.
User interface: (New data → ML model → prediction) Following detailed instructions, the user can input flower dimensions, run code in the Jupyter notebook, and the app returns a prediction helping customers identify their flowers.
The App: A standalone Pycharm (Python) project predicting house prices.
Data → ML model: Labeled housing data trains a multi-linear regression model to predict house prices.
Accuracy Metric: Mean squared error of the model on testing data.
Visualizations: Histograms showing distributions of data features and scatterplots demonstrating data correlations.
User interface: (New data → ML model → prediction) Via console the user can input unseen house data, and the model predicts a house’s price helping a realty firm make investment decisions.
The App: A web app (developed with Juptyer, voila, and deployed on Heroku recommending movies.
Data → ML model: Using movie data, data is vectorized so that Cosine similarity can provide similarity scores between any two movies.
Accuracy Metric: Cosine similarity score on test data, or a plan to measure the app’s accuracy based on future user feedback,
Visualizations: Histograms showing distributions of movie features and samples of Cosine Similarity matrices.
User interface: (New data → ML model → prediction) Using a user-provided movie, the web app returns five recommendations for a user typed movie helping customers find movies to watch. See this movie recommendation example
The App: A hosted Jupyter notebook identifies images as a cat or dog.
Data → ML model: Labeled images are used to train a neural network model to classify images of dogs and cats.
Accuracy Metric: Percent of correct predictions on testing data.
Visualizations: Graphs of training and validation accuracy and loss, a confusion matrix showing model accuracy, and image examples.
User interface: (New data → ML model → prediction) Following detailed instructions, the users upload an image to Jupyter notebook folder deployed on Datalore, and run the app classifying the image as cat or dog.
Data requirements#
Your data must be sufficiently complex and processed for your ML algorithm to function as needed.
Evaluators must be able to access your data.
There are no specific requirements regarding the complexity or nature of your data. However, your application must work and fulfill the organizational need you’ll outline in the task 2 documentation. Therefore, when choosing your raw data, consider carefully any additional time and effort necessary to prepare that data for use. As these extra steps are only needed in so far as the chosen problem and algorithm need them, you may wish to adjust your project or choose a different data set accordingly.
You do not need special permission to use any open-source dataset (see our list). Furthermore, data sets used in previous C964 projects are available for reuse (no list of previously used datasets exists). It’s only required that the data meet the needs of your project and be legally available to use and share with evaluators. For example, using data belonging to a current employer would require submitting a waiver form.
You can use data used for previous projects (submitted by you or others) including any dataset found on kaggle.com.
You do not have to use all the data. Removing columns or rows is permissible.
You can use simulated data.
You only need to apply for IRB review if you are collecting data involving human participants (this is very rare). Otherwise, your project is in IRB compliance.
See a list of openly available data here.
Machine Learning requirements#
You must apply machine learning to data.
You are encouraged to use ML libraries. Provided the source code is available to evaluators, any language or library of your choosing is allowed. However, we do recommend and can give better support for Python. The scikit-learn library is an excellent choice; it is diverse, robust, and has many supplementary resources to help you get started.
Visualization requirements#
You must have three different images helping describe your project.
The purpose of the visuals is to help the reader understand your project, but little is required other than the three images be unique and related to your project. The images can be generated by the code or inserted statically. The visualizations can describe the data or ML algorithm. They can be the same type describing different data subsets or of different types describing the same data. Examples include pie charts, histograms, scatterplots, confusion matrices, etc.
The visualizations are required to be part of the application. However, sometime this may not be ideal, say when the app is intended to customer facing. So it is allowable to submit the code providing the visualizations separate from the main application code.
Scatterplot

Regression Line
Confusion Matrix

Histogram
Histograms
Pie-chart
Scatterplot Matrix

Correlation Matrix
Barplot
Barplot
Line plots

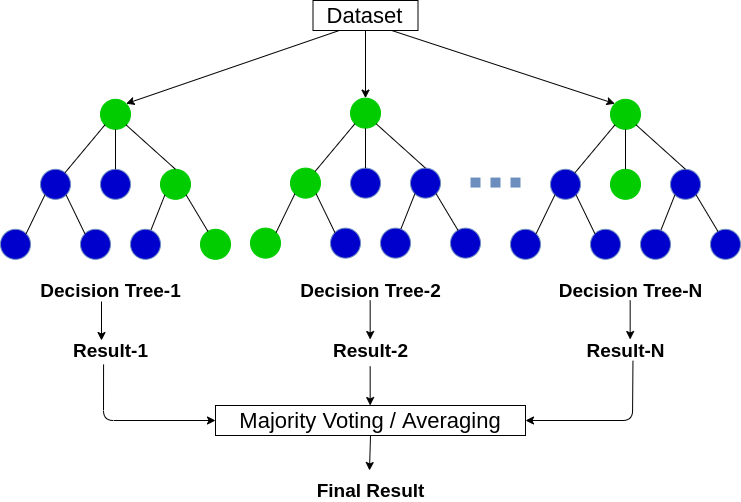
Model Explanation
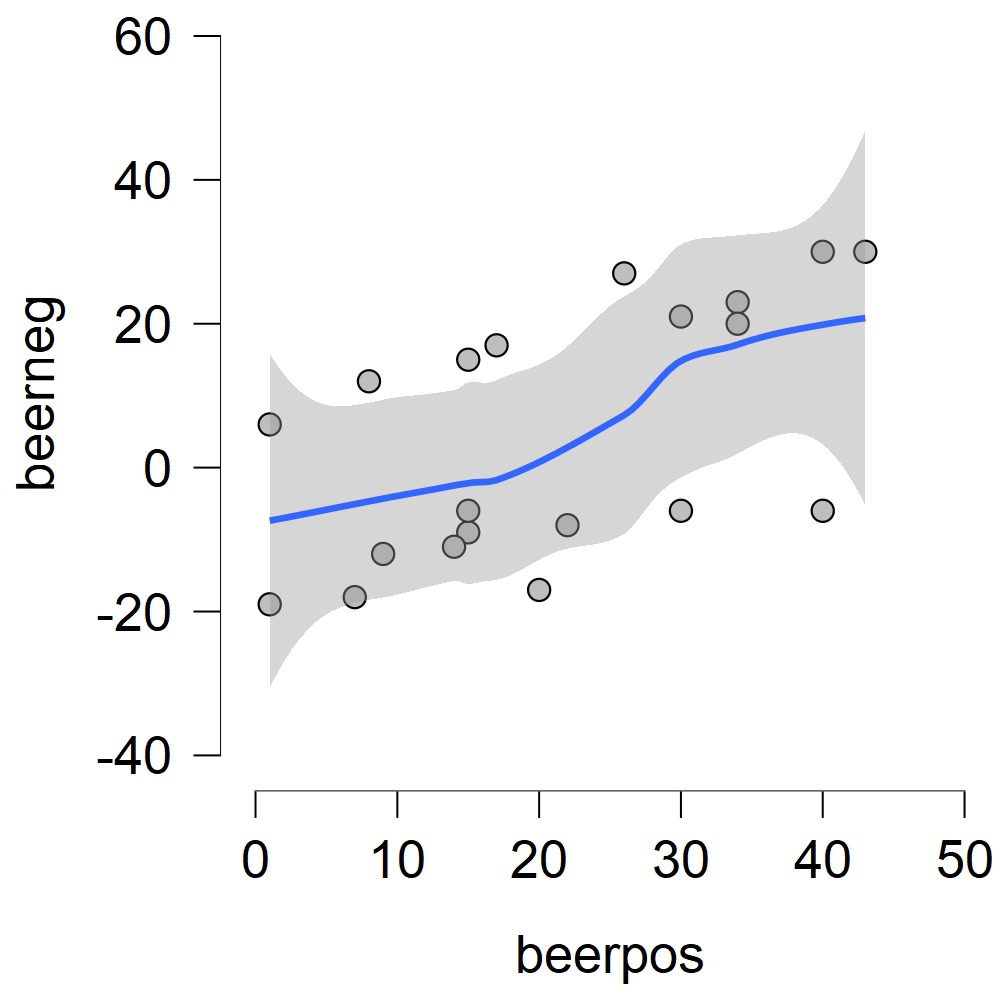
Regression
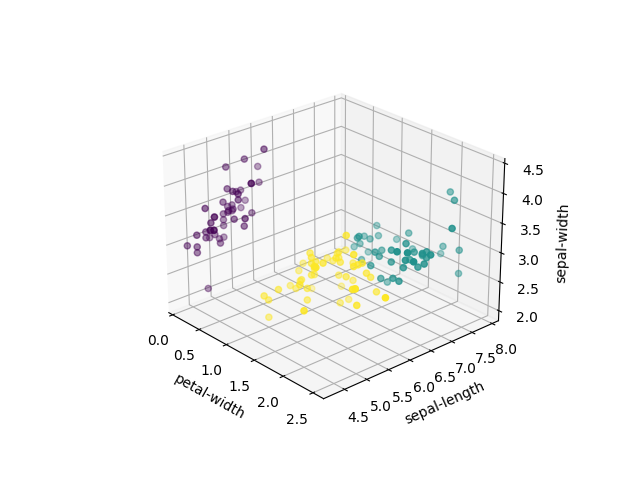
Clustering
User interface requirements#
You must provide a user-friendly interface by which the proposed client can use your application to help solve the problem.
Playing the role of the client, the evaluator will follow your user guide in part D of the documentation. To meet this requirement they should be able to do the following:
Run your application (user-friendly). Your application will be considered “user-friendly” if the evaluator successfully executes and uses your application on a Windows 10 machine following your instructions. They can be instructed to download and install necessary dependencies or software.
Use your application to solve the proposed problem as intended (interface). Most often the interface requirement is met by having some way for the user to provide input and receive output. For example, a user provides weather conditions, and the app returns a prediction of popsicle sales. How the interface is implemented, whether it be widgets, uploaded data, or simple console input; is up to you.
At a minimum, the interface must provide means for the user to provide input and receive feedback. Any method by which you can provide instructions is acceptable. For example:
… Step 10: Next, the user should type the following command into line 57:
mymodel.predict([[temperature, humidity]])in place of ‘temperature’ and ‘humidity’, the user should type the temperature in Fahrenheit and humidity as a percentage for which they’d like a prediction, e.g.,
mymodel.predict([[75, 24.5]])for a temperature of 75 degrees and humidity of 24.5%.
Step 11 Run the code by pressing the ‘Run’ button in the Jupyter Notebook menu or pressing ‘Crtl+Enter’ to the left of block 57. …
See the individual example user guides and guides provided in the completed task 2 document examples.
Coding#
Time to get to work.
Warning
Following tutorials/examples is a great way to learn. But when it comes to writing your own code, don’t copy, paste, and pray. Instead, understand what it’s doing for each line of code and check that it runs as intended. Investing in the extra time will make you a better computer scientist and could save many frustrating hours.

Fig. 2 Code Quality [xkcd, n.d.]#
Start slow. You must learn and incorporate many small but probably new skills into a larger working app -data processing, data analysis, new libraries, and user interface. Learn one new skill, implement it, and check your code before moving on to the next step. Things will start slowly and expect to make mistakes, but things can progress quickly after the initial investment.
Start small and build up#
A suggested path:
Import data and convert it to a data frame (using Pandas).
Explore the data and create some images.
Determine which ML algorithm to start with and choose a supporting library.
Read the library’s documentation and understand the expected data format and usage.
Apply the algorithm to the data, e.g., train it, and create a model.
Apply the model to new data, e.g., a single input.
Create a procedure for the user to apply the model, e.g., provide input.
Add three images, and you have a passing part C after step 7. Then, as time allows, you can go back to step 2, improving the performance and presentation of your application until you are satisfied.
Jupyter Notebook is a great choice for the application’s development and front end. Passing applications often include only the Notebook (.ipynb) and data files. Jupyter Notebooks are a great way to present code and information together. Moreover, they can also be progressively developed into a more polished product. For example, a development path might look like the following:
Python IDE → Jupyter Notebook → notebook with widgets → hosted notebook with widgets → web app.
Provided the minimal app criteria are met, submitting any point along this path will pass part C. You can use whatever language or libraries you like. However, we recommend Python. For ML libraries, the scikit-learn (aka sklearn) is a great choice. In addition to having an extensive collection of ML-specific tools and tutorials, WGU has better faculty support available for both Python and sklearn.
Application Performance#
For supervised methods, you should use a metric to measure accuracy and help improve the model. Knowing which algorithm will perform best requires an understanding of the data and algorithms. However, using a metric, you can quickly compare and experiment with different approaches -usually by changing a few lines of code. Such experimentation can then lead to understanding.
Depending on the method, metrics might similarly be used for unsupervised models, such as Silhouette coefficients for KMeans clustering. Alternatively (and typically), a future development plan for measuring the accuracy of your unsupervised method can be used.
Note
There is no minimal accuracy requirement. At most, evaluators will assess the appropriateness of the metric (or planned metric).
Measuring accuracy (or a plan to do so) will be discussed in detail in the Accuracy Analysis section of part D of your documentation.
FAQ#
Help! I’ve never coded a machine learning project. For C951 task 3, I only had to write about Machine Learning. Where do I learn this?#
Maybe the fastest way to get started is with the video and examples included on this website. Though a minimally passing C950 project (applying a greedy algorithm to hand-picked truckloads) would not be consider ML by many, it meets the criteria for this project as it is an algorithm applied to data. If you have time, Udemy offers some ML courses.
WGU provides access to a very good AI textbook which includes a Machine Learning section. However, it is conceptually focused and includes very little application or practical examples. Furthermore, reading this text might require mathematics not provided in WGU’s BSCS curriculum.
What are the most common reasons for task 2 part C (the app/code) being returned?#
Evaluators cannot get the code to run as intended. This usually happens because of an incomplete or incorrect User Guide or because evaluators can’t access shared links (check the permissions!).
Evaluators are not sure how the code is meant to be used by the “user.” Again, an incomplete or incorrect User Guide is usually the culprit. Adding an explicit example (including example user files when appropriate) helps avoid this issue.
I’ve completed the coding for task 2. Should I send it to my course instructor for review?#
If you have specific questions or concerns -yes. However, if the code runs and meets the minimum app requirements it’s usually best to move on to the documentation. You can continue to tweak and improve the app while comfortably knowing what you have will pass. Recall, you have unlimited submissions. So for both the code and documentation, it’s usually best to submit it as soon as it’s ready and restrict revisions according to the evaluator’s feedback.
For getting help with task 2 part C, see the advice below.
I need help with part C. Who do I contact?#
That depends on what you need help with. For questions about the capstone, how to meet the requirements, evaluator comments, or how to best approach the project to meet your individual goals, contact your assigned course instructor or the capstone team inbox (this inbox supports all IT capstones). However, the capstone team supports all of the IT college capstone projects. As such, your assigned course instructor may not have the technical expertise to answer questions related to computer science or coding. This is particularly so with debugging code, given the wide range of approaches, languages, and libraries available for use.
For technical questions related to code or math, see the BSCS, Software, and other Course Faculty page, and follow these guidelines. Keep in mind, that while these faculty may be subject matter experts in their field, they do not necessarily support the capstone and so may not know the capstone requirements. Hence it is often best to contact your capstone instructor first, so you can appropriately limit the scope of your question(s). When contacting faculty on the BSCS, Software, and other Course Faculty page, follow these guidelines. Keep in mind, that non-capstone faculty love to help but do so as a generosity. Their priority is the students struggling in their supporting courses.
Remember, our job (as educators) is to help you fix your problem -not fix it for you.
What if I start working on task 2 and want to change things? Do I need to resubmit task 1?#
No, not unless it’s an entirely different topic. Minor changes from task 1 to task 2 are expected and allowed without updating the approval form. Evaluators will not rigorously compare tasks 1 and 2 (if at all). Task 2 is where the work is, and even with complete topic changes, at most, you’ll only be asked to revise the approval form (if at all). So never let task 1 dictate what you do in task 2.
How many attempts are allowed for each task?#
You have unlimited attempts for both tasks 1 and 2. However, incomplete submissions or submissions significantly falling short of the minimum requirements may be locked from further submissions without instructor approval. Furthermore, such submissions do not receive meaningful evaluator comments.
What is a descriptive method?#
Anything that describes the data. Histograms, scatterplots, pie charts -all the familiar descriptive statistics techniques are included. ML methods such as k-means clustering can also be descriptive. Whether a method is descriptive or non-descriptive is determined by its use. For example, using a regression line to describe the relationship between variables is descriptive, but using the line to predict a variable or claim a correlation between the variables exist is inferential (non-descriptive).
For task 2, you do not need to explicitly identify descriptive and non-descriptive methods. In almost all cases, the visualizations will satisfy the former and the user interface the latter.
What is a non-descriptive method?#
Anything that infers from the data, e.g., making predictions, recommendations, identifying correlations, inferring from correlations, etc. Also, see the comments above.
What is machine learning?#
That depends on who you ask! But for this project, it is an algorithm applied to data.
For computer science, machine learning is a subfield of artificial intelligence (a subfield of mathematics), broadly defined as the development of machines capable of self-adjusting behavior based on data. However, from the data science perspective, machine learning is generally defined as using algorithms to identify patterns, make predictions, etc., from data. That is, machine learning is a goal, not a technique. So, for example, a data scientist (and the evaluators) consider linear regression machine learning -when it’s used as a prediction model. However, a mathematician would politely (or not so politely) disagree with a 19th-century equation being classified as ML.
Can I use libraries outside the standard (Python, Java, etc.) installation?#
Yes! Unlike C950 (Data Structures & Algorithms II), you are allowed and encouraged to use outside libraries. All the major languages, but particularly Python, have a wide array of highly developed ML tools. The C964 capstone is about applying these tools -not their development.
What language, libraries, and platforms should I use?#
You can use whatever you like. However, we strongly recommend Python and the scikit-learn (aka sklearn) library. In addition to having an extensive collection of ML-specific tools and tutorials, WGU has better faculty support for these. Jupyter Notebook (a browser-based IDE designed for this type of project) is a great place to start for the app’s development and front end. Passing applications are often submitted as the Notebook (.ipynb) and data files. Jupyter Notebooks are a great way to present code and information together, but they can also progressively be developed into a more polished product. Students are often tempted to use Java because of their JavaFX experience in software II, but a GUI is not required, and Python is better suited.
A development path might look like the following:
Python IDE → Jupyter Notebook → notebook with widgets → hosted notebook with widgets → web app.
Provided the minimal app criteria are met, submitting at any point along this path will pass part C.
What sort of user interface do I need? Do I need a GUI?#
No, a GUI is not required. Your app must be usable by the “client” to solve the proposed problem. If the evaluators can run your app as intended, playing the role of the “client,” following your user guide, then your app will be considered to have a user-friendly interface. This can be done through a GUI and widgets, but using the command line or reading user data from a local directory will also suffice.
My project exceeds the 200 MB limit. How can I submit it?#
This is covered in more detail here. As you might guess, this is a common issue. Many models and datasets will exceed the 200 MB upload limit. Evaluators need access to everything necessary to develop and run your project, and those files cannot be modifiable after being submitted.
For webpages or hosted Jupyter notebooks, submit the url link (provide the link and instructions for your app in your user guide of part D) but also submit the html or .ipynb files. For large models, provide instructions and code to locally build the model and how access to the data as described as above. If build times are long, you might provide a link to the completed model as a courtesy to the evaluator.
Always submit the data directly if it is less than 200 MB. For larger data sets not modifiable by the student (e.g., data from Kaggle.com, Data.gov, sklearn, etc.), it is acceptable to submit a link for the data source or import the data directly with your code. For large data sets modifiable by the student (say in a GitHub repo), then you should provide a subset of the data not exceeding the 200 MB limit. The project’s documentation and performance assessment should be based on the full data.
Use of Google Colab is acceptable, but upload the source code and check the share permisisons.
I only have a Linux (or Mac) machine. Will evaluators be able to run my code?#
Technically (and unfortunately), we are a “Windows” university, and all submitted projects should be able to run in Windows. However, being Windows-compatible is nowhere specifically required in the C964 rubric, and doing so would be a little silly for a computer science program. That said, WGU evaluators are only issued Windows 10 machines, and they may have difficulty running a Linux or Mac app without special instructions. Therefore, we recommend that your user guide provide explicit instructions for a Windows 10 user to run your code, such as using a virtual machine, a remote machine, or using a Linux subsystem. Provide a note when submitting to Assessments and alert your course instructor.
How complex does my data, algorithm, or model need to be?#
It must be complex enough to meet the needs of your project. There is no explicit minimal complexity for any of these items. However, the model must meet the needs of the “organizational need” and the data must be appropriate for developing the model which could indirectly impose a minimal complexity. For example, a supervised model requires two variables.
Are there any restrictions on which datasets I can choose?#
Only that data must be legally available to use and share with evaluators. For example, using data belonging to a current employer would require submitting a waiver form.
You can use any dataset found on kaggle.com.
You can use simulated data.
You can use data used for previous projects (submitted by you or others).
You only need to apply for IRB review if you are collecting data involving human participants (this is very rare). Otherwise, your project is in IRB compliance.
Can I use my C950 project for C964?#
Yes. You can use any of your own academic or professional work for C964 including the C950 project (Data Structures & Algorithms II). Though the document (Task 2 parts A, B, and D) will need some adjustment, the coding portion of C950 almost meets all the requirements of the C964 application (Task 2 part C) -it only lacks visualizations. Referring to the Task 2 part C page, the C964 application needs the following:
Data → ML model: C950 applies a reinforced learning algorithm to the distance and package data.
Accuracy Metric: The total miles. The maximum allowed miles for C950 is 120, which WGU Assessment Department has already determined to be “efficient.”
Visualizations: This will need to be added, but any three pictures will meet the requirements.
User Application: The console user interface required for C950 allows the user to provide input and apply the algorithm toward solving the problem.
So only the three images will need to be added. Furthermore, you are free to adjust the distance and package data as desired. For example, dropping some of the delivery restrictions requiring different trucks or certain packages to be delivered together, and will be easier to apply a more sophisticated algorithm. Say a Monte Carlo method such as Simulated Annealing.

Can I use my C951 task 1 or 2 for C964?#
Yes. You can use any of your own academic or professional work for C964 including the C950 project (Data Structures & Algorithms II). However, C951 Tasks 1 (chatbot) and 2 (rescue robot) can be passed without applying a mathematically based algorithm which is necessary to pass C964 (no C951 task requires AI). While chatbots are often trained and improved with ML/AI methods, it’s difficult to acquire sufficient user data within students’ typical timeframe. An algorithm is easier to employ in C951 Task 2, but the application would be limited to the CoppeliaSim simulation software which may make meeting the user application requirements of C964 difficult. Furthermore, CoppeliaSim’s dependency on Lua makes the application of ML libraries problematic. For these reasons and others, we do not recommend using either of these projects for C964 -unless the C951 projects far exceed their requirements and meet the C964 requirements as is.
Can I use my C951 task 3? Should I use it?#
You can reuse anything you’ve done of your own academic or professional work, including copying verbatim from C951 task 3. If it’s convenient, feel free to do it. But at best, the time saved is little. At worst, you might get bogged down trying to work on two projects simultaneously and going with an unnecessarily complex C964 topic. If you have time, consider completing C964 first, as parts A and B of task 2 can always be used verbatim for task 3 of C951.
Here are some points to consider:
C951.3 is just a written project, typically around five pages (I’m guessing; ask your C951 instructor), and can be completed in a single afternoon. Comparatively, C964 requires a working machine learning application and accompanying documentation, typically around 20 pages.
C951.3 only relates to parts A and B of C964.2. These parts are just a framework for providing a general audience and purpose for the ML application. If present, these parts almost always pass. Furthermore, they’ll have to be at least partially rewritten anyways. Parts C and D of C964 are what evaluators care about, but C951.3 has no corresponding parts C and D.
Rewriting C951.3 content for a different C964 topic takes little additional work.
As it’s just a written project, students often pick a complex topic for C951.3. But then they feel pressured to use the same complex topic for C964 and struggle with creating the app.
Trying to comprehend two projects at once is just more difficult.
Whatever you do for C964 can meet the requirements of C951 task 3. If you have plenty of time, completing C964 first might be the best option.
The rubric and task directions has items not explained on this website, e.g., “security features,” “interactive queries,” “monitoring tools,” etc. Do these need to be included?#
The official rubric and directions were written to map the project’s elements to specific competencies. However, to allow for a broad range of projects its language is necessarily also broad. For more specifics, we recommend referring to the guidelines on this webpage and the Task 2 template. Following the official directions will meet all the requirements, but be aware that some items might not be applicable to your project or be inherently met by other items. For example, in part C:
The descriptive and nondescriptive requirement is met by the visualization and decision support functionality respectively.
Visualization functionality and monitoring tools are inherently part of tools used to create visualizations and code.
A solution using a mathematically based algorithm to data both suffices as ML and provides a “non-descriptive” method.
The guidance on this website serves to provide some specificity to help students overworking or misinterpreting requirements. For more details of the Task 2 requirements see:
For the documentation, preserve the template’s section titles, and order, and submit all four parts as a single document (preferably a .pdf). With a long, complicated document, aligning content to competencies presents a challenge. Don’t make things difficult for the evaluator by spreading the content over several documents in an unfamiliar format. Your C964 course instructor team has collaborated with evaluators to ensure the explanations on this webpage align with how the assessment’s requirements are assessed. If anything needs further explanation, please ask us! Contact your C964 course instructor.