Accuracy Analysis (for classification)#
In the Accuracy Analysis section of part D of your project’s documentation, you will need to define and discuss the metric for measuring the success of your application’s algorithm. The metric for measuring a supervised classification model’s accuracy is straightforward. We use the ratio of correct to total predictions:
Most libraries have builtins for this; see sklearn metrics.
from sklearn import metrics
score = metrics.accuracy_score(y_train, predictions)
score
0.99
99% is pretty good (actually too good), but we tested the model using the same data used to train the model.
svm_model.fit(X_train,y_train_array)
Testing with the training data is not good practice. Recall the test data was set aside for this purpose.
#y_test_array = y_test['type'].values #Converts the dataframe to an array.
#predictions using test data
predictions_test = svm_model.predict(X_test)
score2 = metrics.accuracy_score(y_test,predictions_test)
score2
0.94
Using the test data we set aside, \(94\%\) of the predictions are correct.
A confusion matrix further breaks down the predictions by categories, helping develop better models and providing another visualization.
from sklearn.metrics import ConfusionMatrixDisplay
ConfusionMatrixDisplay.from_estimator(svm_model, X_test, y_test);
# cm = metrics.confusion_matrix(y_test, predictions_test, labels=svm_model.classes_)
# disp = metrics.ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=svm_model.classes_)
# disp.plot();
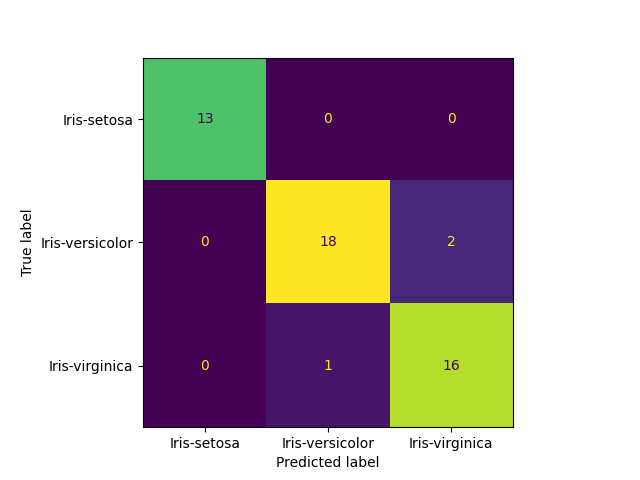
94%, which still seems fairly good (but what is “good” accuracy?), but if selecting the test data randomly (try random_state=42), accuracy may improve on the test data because the set is relatively small and the model is fairly accurate. Using these results, the model can be further refined. However, continually tweaking parameters according to the test data results means we are back to studying from the answers, i.e., reintroducing the risk of overfitting. To deal with this, a third set can be withheld, called a “validation set,” to analyze the final results.
But Partitioning available data into three sets reduces the available data for training the model, making results more dependent on the random selection of training, testing, and validation sets. Cross-validation addresses this issue by resampling the data. Again, this is optional but could be very useful, particularly for small data sets.
from sklearn.model_selection import KFold, cross_val_score
k_folds = KFold(n_splits = 5, shuffle=True)
# The number of folds determines the test/train split for each iteration.
# So 5 folds has 5 different mutually exclusive training sets.
# That's a 1 to 4 (or .20 to .80) testing/training split for each of the 5 iterations.
scores = cross_val_score(svm_model, X, y)
# This shows the average score. Print 'scores' to see an array of individual iteration scores.
print("Average Score: ", scores.mean())
Average Score: 0.9666666666666666
More testing and development#
Now we can further develop the model until our heart’s content. Refine the model through a cyclic process guided by knowledge and experimentation. Research, try different algorithms, and adjust. They’ve built the libraries for this so that the additional coding effort will be lite. These steps are optional and not required, but this is where things become more exciting and challenging.
Machine learning is a mix of art and science, requiring a balance of knowledge, intuition, and lots of experimentation. Research, play around, tweak, and constantly re-run code.
Logistic Regression#
Logistic regression predicts the probability of something being in a category (hence its “regression” name). That probability indicates whether it’s in that category, e.g., \(.65 > .50 \Rightarrow \text{yes}\) (so it’s also a classification method). We’ll use sklearn logistic regression to do the latter.
from sklearn.linear_model import LogisticRegression
log_model = LogisticRegression(random_state=0).fit(X_train, y_train)
That’s right, a new model in just two lines of code. This is typical if you stay within the same library. From here we can test, improve, and compare.
predictions_log = log_model.predict(X_test)
score = metrics.accuracy_score(y_test, predictions_log)
score
0.92