{
"cells": [
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"Running Python code requires a running Python kernel. Click the {fa}`rocket` --> {guilabel}`Live Code` button above on this page to run the code below.\n",
"\n",
"```{warning}\n",
"🚧 This site is under construction! As of now, the Python kernel may not run on the page or have very long wait times. Also, expect typos.👷🏽♀️\n",
"```\n",
"(sup_class_ex)=\n",
"# Example: Supervised Classification App\n",
"\n",
"A supervised classification method fits the project requirements well and is so a good place to start. The nature of your Data and organizational needs dictate which methods you can use. So what type of data works with supervised classification methods? \n",
"\n",
"- One of the features (columns) contains mutually exclusive *categories* you want to predict (the dependent variable).\n",
"- At least one other feature (the independent variable(s)).\n",
"\n",
":::{margin}\n",
"Classifying non-mutually exclusive categories is called *multi-label* or *mult-output* classification. Not to be confused with *multiclass* classification presented in this example, multi-label classification requires different techniques, particularly with measuring accuracy. See [Introduction to Multi-label Classification](https://www.geeksforgeeks.org/an-introduction-to-multilabel-classification/) for more information. \n",
":::\n",
"\n",
"This will be a simple example. Simple data. Simple model. Simple interface. However, it does demonstrate the minimum requirements for [part C](task2c). We'll also show how things can progressively be improved, building on the *working* code. Simple is a great place to start -scaling up is typically easier than going in the other direction. \n",
"\n",
"\n",
"  \n",
"
\n",
"  \n",
"
\n",
"
\n",
"\n",
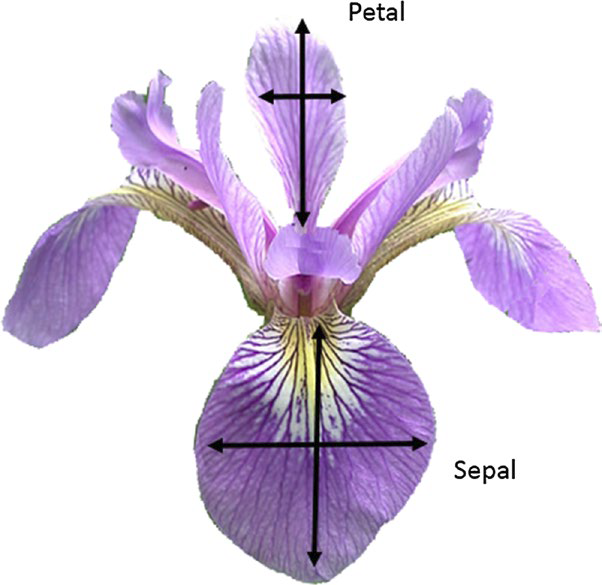
"Let's look at the famous [Fisher's Iris data set](https://en.wikipedia.org/wiki/Iris_flower_data_set): "
]
},
{
"cell_type": "code",
"execution_count": 2,
"id": "b053efd1",
"metadata": {
"tags": [
"hide-input"
]
},
"outputs": [
{
"data": {
"text/html": [
"\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" sepal-length | \n",
" sepal-width | \n",
" petal-length | \n",
" petal-width | \n",
" type | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" 5.1 | \n",
" 3.5 | \n",
" 1.4 | \n",
" 0.2 | \n",
" Iris-setosa | \n",
"
\n",
" \n",
" | 1 | \n",
" 4.9 | \n",
" 3.0 | \n",
" 1.4 | \n",
" 0.2 | \n",
" Iris-setosa | \n",
"
\n",
" \n",
" | 2 | \n",
" 4.7 | \n",
" 3.2 | \n",
" 1.3 | \n",
" 0.2 | \n",
" Iris-setosa | \n",
"
\n",
" \n",
" | 3 | \n",
" 4.6 | \n",
" 3.1 | \n",
" 1.5 | \n",
" 0.2 | \n",
" Iris-setosa | \n",
"
\n",
" \n",
" | 4 | \n",
" 5.0 | \n",
" 3.6 | \n",
" 1.4 | \n",
" 0.2 | \n",
" Iris-setosa | \n",
"
\n",
" \n",
" | ... | \n",
" ... | \n",
" ... | \n",
" ... | \n",
" ... | \n",
" ... | \n",
"
\n",
" \n",
" | 145 | \n",
" 6.7 | \n",
" 3.0 | \n",
" 5.2 | \n",
" 2.3 | \n",
" Iris-virginica | \n",
"
\n",
" \n",
" | 146 | \n",
" 6.3 | \n",
" 2.5 | \n",
" 5.0 | \n",
" 1.9 | \n",
" Iris-virginica | \n",
"
\n",
" \n",
" | 147 | \n",
" 6.5 | \n",
" 3.0 | \n",
" 5.2 | \n",
" 2.0 | \n",
" Iris-virginica | \n",
"
\n",
" \n",
" | 148 | \n",
" 6.2 | \n",
" 3.4 | \n",
" 5.4 | \n",
" 2.3 | \n",
" Iris-virginica | \n",
"
\n",
" \n",
" | 149 | \n",
" 5.9 | \n",
" 3.0 | \n",
" 5.1 | \n",
" 1.8 | \n",
" Iris-virginica | \n",
"
\n",
" \n",
"
\n",
"
\n",
" \n",
" \n",
" | | \n",
" sepal-length | \n",
" sepal-width | \n",
" petal-length | \n",
" petal-width | \n",
" type | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" 5.1 | \n",
" 3.5 | \n",
" 1.4 | \n",
" 0.2 | \n",
" Iris-setosa | \n",
"
\n",
" \n",
" | 1 | \n",
" 4.9 | \n",
" 3.0 | \n",
" 1.4 | \n",
" 0.2 | \n",
" Iris-setosa | \n",
"
\n",
" \n",
" | 2 | \n",
" 4.7 | \n",
" 3.2 | \n",
" 1.3 | \n",
" 0.2 | \n",
" Iris-setosa | \n",
"
\n",
" \n",
" | 3 | \n",
" 4.6 | \n",
" 3.1 | \n",
" 1.5 | \n",
" 0.2 | \n",
" Iris-setosa | \n",
"
\n",
" \n",
" | 4 | \n",
" 5.0 | \n",
" 3.6 | \n",
" 1.4 | \n",
" 0.2 | \n",
" Iris-setosa | \n",
"
\n",
" \n",
" | ... | \n",
" ... | \n",
" ... | \n",
" ... | \n",
" ... | \n",
" ... | \n",
"
\n",
" \n",
" | 145 | \n",
" 6.7 | \n",
" 3.0 | \n",
" 5.2 | \n",
" 2.3 | \n",
" Iris-virginica | \n",
"
\n",
" \n",
" | 146 | \n",
" 6.3 | \n",
" 2.5 | \n",
" 5.0 | \n",
" 1.9 | \n",
" Iris-virginica | \n",
"
\n",
" \n",
" | 147 | \n",
" 6.5 | \n",
" 3.0 | \n",
" 5.2 | \n",
" 2.0 | \n",
" Iris-virginica | \n",
"
\n",
" \n",
" | 148 | \n",
" 6.2 | \n",
" 3.4 | \n",
" 5.4 | \n",
" 2.3 | \n",
" Iris-virginica | \n",
"
\n",
" \n",
" | 149 | \n",
" 5.9 | \n",
" 3.0 | \n",
" 5.1 | \n",
" 1.8 | \n",
" Iris-virginica | \n",
"
\n",
" \n",
"
\n"
],
"text/plain": [
""
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"##preserves Jupyter preview style (the '...') after applying .style. This is for presentation only. \n",
"def display_df(dataframe, column_names, highlighted_col, precision=2):\n",
" pd.set_option(\"display.precision\", 2)\n",
" columns_dict = {}\n",
" for i in column_names:\n",
" columns_dict[i] ='...'\n",
" df2 = pd.concat([dataframe.iloc[:5,:],\n",
" pd.DataFrame(index=['...'], data=columns_dict),\n",
" dataframe.iloc[-5:,:]]).style.format(precision = precision).set_properties(subset=[highlighted_col], **{'background-color': 'yellow'})\n",
" pd.options.display.show_dimensions = True\n",
" display(df2)\n",
"\n",
"#display dataframe with highlighted column \n",
"display_df(df, column_names, 'type', 1)"
]
},
{
"attachments": {},
"cell_type": "markdown",
"id": "96de1903-332e-49f8-b7e7-96b50fc940ee",
"metadata": {
"tags": []
},
"source": [
":::{sidebar} Watch\n",
"\n",
":::\n",
"\n",
"The highlighted column, **type** provides a category to predict/classify (dependent variables), and the non-highlighted columns are something by which to make that prediction/classification (independent variables)."
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3 (ipykernel)",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.11.1"
},
"vscode": {
"interpreter": {
"hash": "3ff4b9f9a77e43d422b45ad0e34f66a3a995e732d437005df0ccbc0093bddc0e"
}
}
},
"nbformat": 4,
"nbformat_minor": 5
}